基本概念
支持度 (Support) —— “这东西流行吗?”
- 定义:项集 在所有事务中出现的频率 2。
- 公式:
- 例子:
- 例如数据中,“牛奶” 在 TID 1, 4, 5, 7, 8, 9 中出现了,共 6 次。
- 那么 {牛奶} 的支持度 = 。
- 频繁项集 (Frequent Itemset):如果一个项集的支持度 我们设定的最小支持度 (min_support),它就是频繁的,值得挖掘 3。
置信度 (Confidence) —— “买了这个,还会买那个吗?”
- 定义:在包含 X 的情况下,同时包含 Y 的概率(条件概率) 4。
- 公式:
- 例子:
- 假设我们要验证规则:{牛奶} {面包}
- 同时买 {牛奶, 面包} 的次数是 4 次 (TID 1, 4, 5, 8)。
- 单独买 {牛奶} 的次数是 6 次。
- 置信度 =
- 强规则 (Strong Rule):如果置信度 最小置信度 (min_confidence),这条规则就是强规则 5
算法
FP-Growth 的核心思想是:把庞大的交易数据库,压缩成一棵紧凑的树 (FP-Tree),并且保留所有关联信息。
步骤 1:排序与过滤 (Sorting & Filtering)
构建树之前,必须对数据进行清洗。
- 统计所有商品的频率。
- 删除不满足最小支持度的商品。
- 关键点:对于每一条交易记录,将剩下的商品按照频率从高到低排序 。
- 为什么? 高频商品(如鸡蛋、薯片)放在树的顶部,可以被更多的路径共享,从而最大程度地压缩树的体积。
步骤 2:插入树 (Insertion)
想象你在画这棵树:
- Root 节点:树的根,为空。
- 路径共享:当插入一条新记录(如 {薯片, 鸡蛋, 面包})时:
- 如果树根下已经有“薯片”节点,就不创建新节点,而是让那个“薯片”节点的计数 +1。
- 如果接着往下已经有“鸡蛋”,计数 +1。
- 如果没有“面包”,则创建一个新的“面包”节点,计数为 1。
步骤 3:头指针表 (Header Table) —— C++ 实现的关键
这是容易忽略的地方。为了快速挖掘,不能每次都从 Root 遍历。 我们需要一个侧面的表格(Header Table),如图中列表 :
- 它存储了每个商品(薯片、鸡蛋…)的头指针。
- 横向链表 (Side-links):树中所有相同的商品节点(比如树里有3个不同的“面包”节点),要通过指针串连起来。
- C++ 思考:这需要在 Node 结构体中加一个
Node* nodeLink指针。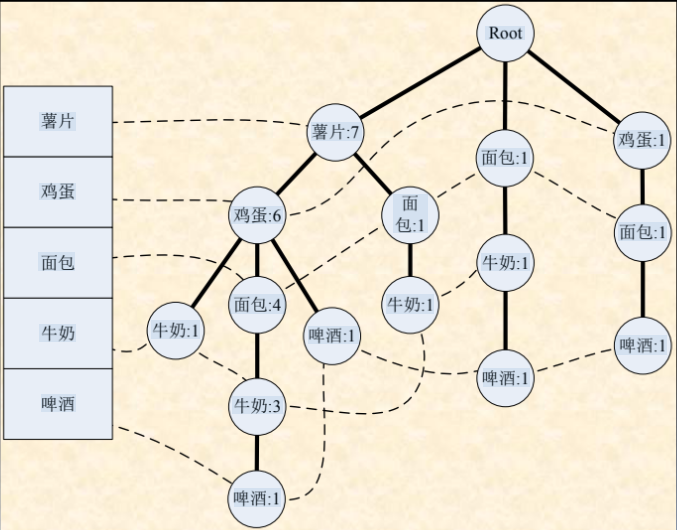
挖掘
树建好了,怎么挖出规则? 这是一个分治 (Divide and Conquer) 的策略。
- 从底向上:从 Header Table 中频率最低的商品开始(例如“啤酒”)。
- 寻找条件模式基 (Conditional Pattern Base)
- 通过横向链表找到树中所有的“啤酒”节点。
- 向上追溯,找到所有通往“啤酒”的路径(前缀路径) 。
- 例如:路径可能是
{薯片:1, 鸡蛋:1, 面包:1}指向{啤酒:1}。
- 构建条件 FP-Tree:
- 把这些前缀路径看作一个新的小数据库。
- 在这个小数据库上,再次统计频率、过滤、建树。
- 递归:
- 在这个“小树”上重复上述过程,直到树为空。
- 这就挖掘出了所有包含“啤酒”的频繁项集。