实现工具调用(Tool Calling)
-
设计工具:你必须实现至少两个工具。当用户提出相关需求时,你的 Agent 必须能够识别并调用相应的工具。
qwen 的工具调用整合了 OpenAI,所以可以看 OpenAI 的使用文档:函数调用 - OpenAI 中文文档,写得比较简略;openai-python/api.md at main · openai/openai-python 仓库,详细但是冗杂
基本步骤:
- 创建助手,以调用外部 API 来回答问题(定义函数)
- 将自然语言转换为 API 调用
- 从文本中提取结构化的数据
-
工具1:天气查询工具
可以使用爬虫实现,也可以寻找相应的
api提供商- 功能:接受城市名作为参数。
- 返回:指定城市的实时天气信息,包括温度、天气状况(晴、多云、雨等)和湿度。
- 用户交互示例:当用户问“北京今天天气怎么样?”时,Agent 必须识别出“北京”并调用此工具,然后返回天气信息。
注册接口:天气预报查询接口_天聚地合
1 2 3 4 5 6 7 8 9 10 11WEATHER_API_KEY = "..." def get_weather(city: str) -> str: url = f"http://apis.juhe.cn/simpleWeather/query?city={city}&key={WEATHER_API_KEY}" response = requests.get(url) data = response.json() if data.get("reason") == "查询成功!": result = data["result"] return (f"{city}当前天气:{result['realtime']['info']}," f"温度:{result['realtime']['temperature']}℃," f"湿度:{result['realtime']['humidity']}%") return f"查询天气失败:{data.get('reason', '未知错误')}"-
工具2:网络搜索工具
可以使用Searxng,也可以使用其它专业的
api- 功能:接受关键词作为参数。
- 返回:基于关键词的网络搜索结果摘要。
- 用户交互示例:当用户问“2024 年奥运会在哪里举办?”时,Agent 能够使用此工具进行搜索并给出答案。
试了自己的 searxng,可能是格式问题跑不通,换了个 API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33def web_search(query: str) -> str: # DuckDuckGo 免费搜索 API(无需注册,直接使用) url = "https://api.duckduckgo.com/" params = { "q": query, "format": "json", "no_html": 1, # 不返回 HTML 内容 "no_redirect": 1 # 不返回跳转链接 } try: response = requests.get(url, params=params, timeout=10) response.raise_for_status() # 检查 HTTP 状态码(如 404、500 会报错) except requests.exceptions.RequestException as e: return f"搜索请求失败:{str(e)}" try: data = response.json() except requests.exceptions.JSONDecodeError: return "搜索结果解析失败:返回内容不是有效的 JSON" # 提取结果(DuckDuckGo 的 JSON 结构与 SearXNG 不同) summary = [] # 1. 优先取 "Abstract"(摘要) if data.get("Abstract"): summary.append(f"摘要:{data['Abstract']}") # 2. 再取 "RelatedTopics"(相关主题)的前 2 条 for topic in data.get("RelatedTopics", [])[:2]: if "Text" in topic: summary.append(f"- {topic['Text']}") if not summary: return "未找到相关搜索结果" return "\n".join(summary)
实现记忆功能(Memory)
-
功能:你的 Agent 必须能够记住之前的对话内容,并在后续的交互中利用这些信息。
-
用户交互示例:
- 用户:“今天上海天气怎么样?”
- Agent:“上海今天晴,气温 25 度。”
- 用户:“那明天呢?”
- Agent 必须能够理解“那明天呢?”是关于“上海天气”的追问,并给出正确的答案。
记忆管理:用
message[]存储以前对话的信息
|
|
完整示例代码
将工具调用、记忆整合:
|
|
效果:

多 Agent 协同工作
- 场景:设计至少两个不同的 Agent 角色,让它们在完成一个共同任务时能够互相协作。
参考 openai-sdk 文档:编排多个 Agents - OpenAI Agents SDK - 中文文档
实现要点:
- 需要设计一个消息总线或队列,让 Agent A 能把任务指令发给 Agent B,Agent B 也能把结果回传给 Agent A。
- 每个 Agent 需要有角色专属的 Prompt(提示词),让其记住自己的分工
- 工具需要有统一的调用接口
- Agent 角色设计:
- Agent A(规划者):负责分解任务,将任务分配给其他 Agent,并综合最终结果。
- Agent B(执行者):专门负责调用工具和执行具体操作。
- 协作流程示例:
- 用户:“请帮我查一下,北京明天的天气,然后告诉我这个城市都有哪些著名的 IT 公司。”
- **Agent A(规划者)**接收请求,将其分解为两个子任务:
- 子任务1:查询北京明天的天气。
- 子任务2:查询北京的著名 IT 公司。
- Agent A 将子任务1分配给Agent B(执行者),要求其调用“天气查询工具”。
- Agent A 再次将子任务2分配给Agent B,要求其调用“网络搜索工具”。
- Agent A 收到两个子任务的执行结果后,将它们整合,并以流畅的语言回答用户。
与平时的代码不同,用 Agent 需要把部分代码功能交给 Ai 去处理
完整示例代码
|
|
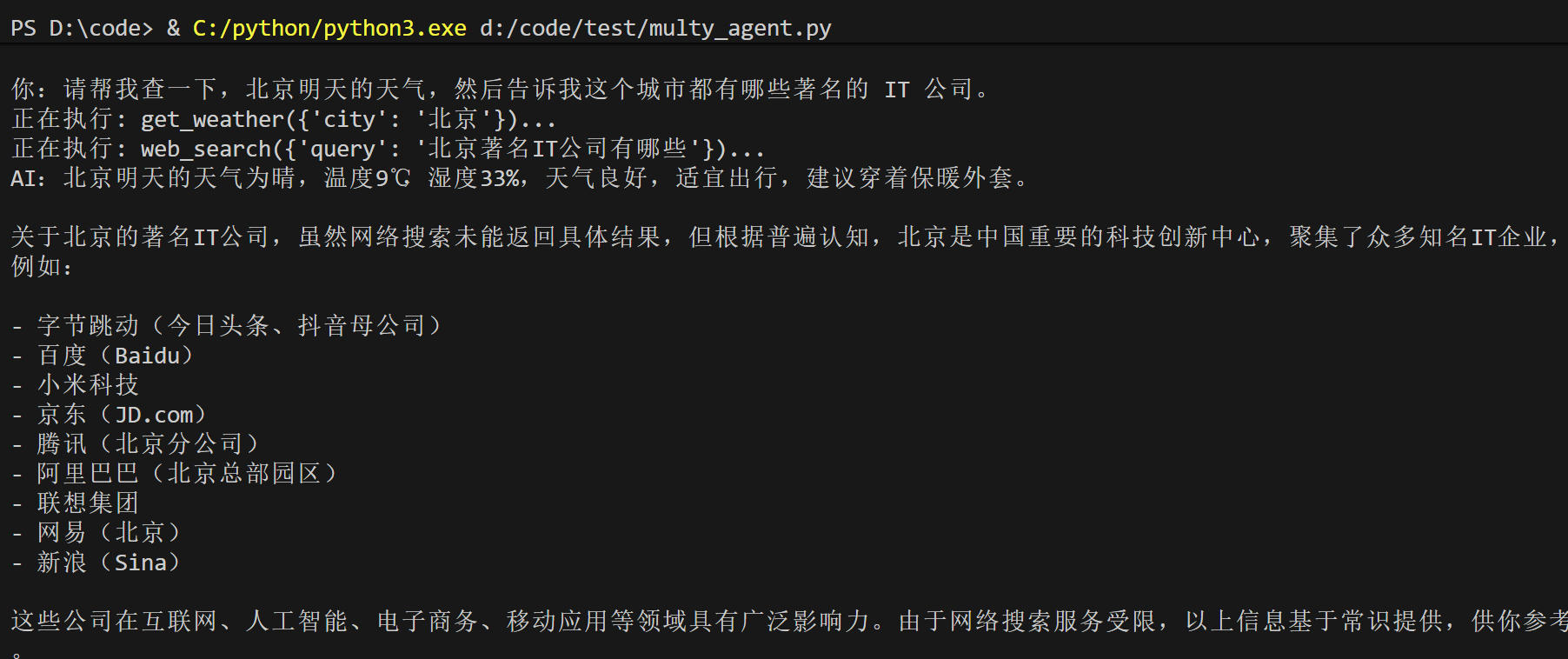
不知道为什么搜索又出了问题
实现任意形式的知识库
- 功能:构建一个外部知识库(可以是简单的文本文件、Markdown 文档,甚至一个小型数据库)。
- 集成:将知识库集成到你的 Agent 系统中,使其能够通过检索知识库来回答问题。
- 用户交互示例:
- 用户:“什么是 DevOps?”
- Agent 能够通过检索你提供的知识库,而不是纯粹依赖 LLM 的通用知识,来回答这个问题。这展示了 Agent 能够利用私有数据或特定领域数据来提供更精确和定制化的答案。
实现:
需要用到预训练模型(这里用
paraphrase-multilingual-MiniLM-L12-v2)来识别语义,将语义相近的文本转化为数值相近的向量
- 导入 SentenceTransformer 模型
需要手动处理模型,将文本处理成可理解的嵌入向量
还有用向量计算内容相关性等知识……不太懂
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36# 大致的关键代码 def __init__(self, kb_path="knowledge_base.md"): self.kb_path = kb_path # 知识库文件路径 self.model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') # 加载预训练模型 self.entries = [] # 存储解析后的知识库条目(标题+文本) self.embeddings = [] # 存储文本的嵌入向量(计算机可理解的“数字表示”) self.load_and_process() # 启动加载与处理流程 # 还需要手动处理 entry、text 等内容 def load_and_process(self): # 检查文件是否存在,不存在则创建示例知识库 if not os.path.exists(self.kb_path): self.create_sample_kb() # 读取文件内容 with open(self.kb_path, 'r', encoding='utf-8') as f: content = f.read() # 按Markdown标题分割条目(核心解析逻辑) entries = re.split(r'\n# ', content) # 用“换行+# ”分割内容(Markdown一级标题格式) if entries and entries[0].strip() == '': # 处理开头可能的空字符串 entries = entries[1:] # 提取每个条目的标题和文本,存入self.entries for entry in entries: lines = entry.split('\n', 1) # 按第一个换行分割(标题和正文分离) title = lines[0].strip() # 标题(如“DevOps”) text = lines[1].strip() if len(lines) > 1 else "" # 正文内容 self.entries.append({"title": title, "text": text}) # 生成嵌入 if self.entries: # 将每个条目的“标题+文本”拼接成完整字符串 texts = [f"{e['title']}: {e['text']}" for e in self.entries] # 用模型将文本转化为向量(嵌入),存储到 self.embeddings self.embeddings = self.model.encode(texts, convert_to_tensor=True)
完整示例代码
|
|
勉强跑通,但是具体的实现不太了解,感觉接口有点复杂了
knowledge_base.md:
1 2# DevOps DevOps是一个大笨蛋
效果:

知识缺漏比较多,先到这里吧