初识
-
分布式的开源搜索引擎
-
提供 Restful 接口,所有语言均可调用
ELK技术栈:
- 结合 kibana(可视化)、Logstash、Beats
- 用于日志分析、事实监控等
倒排索引
正向索引:
- 传统数据库使用,查询需要逐一遍历
倒排索引:
- document:文档,每条数据就是一个文档
- term:词条,由文档按语义划分,有限且唯一
- 先搜词条,再根据词条找文档
IK分词器
作为 ES 插件导入
根据现有词典(可拓展)对文档进行划分
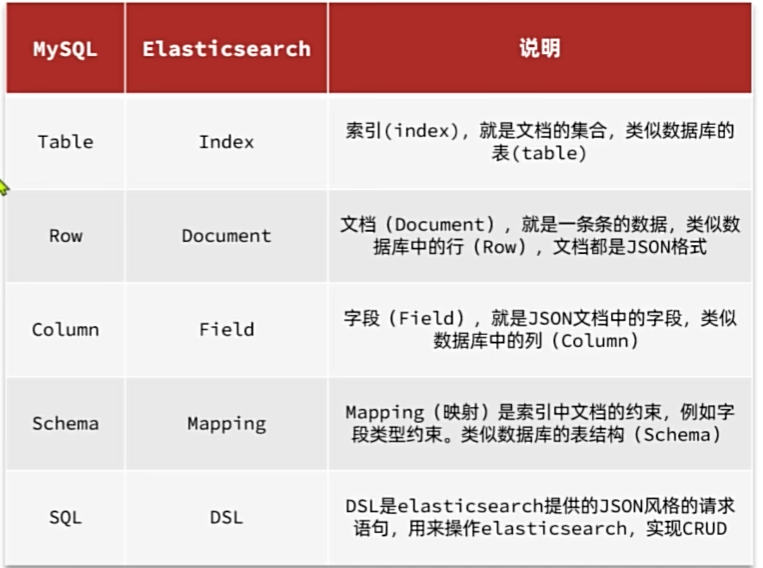
基础概念
索引库:
- 相同类型的文档(Json存储)的集合
映射:
- 索引库中对文档的约束
mapping 属性
-
type:字段数据类型
-
index:是否创建索引
-
analyzer:分词器
-
propertis:嵌套的子字段
索引库操作
RESTFUL 规范
- 不同请求方式对应不同请请求类型
创建索引库和mapping的请求语法如下:
|
|
支持 put、get、delete
文档操作
新增文档:
|
|
修改
- put 全量修改,先删除再新建
- post 增量修改
批处理
|
|
DSL 查询
分类:
- 叶子查询:特定字段查询特定值
- 复合查询:逻辑方式组合叶子查询
基本语法:
|
|
叶子
- 全文检索:分词
- match 查询
- mult_match 允许同时查询多个字段
- 精确查询:不分词,直接精确匹配
- term 查询,整体到词条中寻找
- range
- 地理查询:用于搜索地理位置
复合
- 基于逻辑运算组合叶子
- bool:子句must、should、must_not、filer
- 基于算法修改查询时的文档相关性算分,从而改变排名
- function_score
- dis_max
排序和分页
排序:
- 添加
sort标签,默认按照 _score 排序
分页:
- 添加
from 、size
深度分页问题:
- es 一般对数据进行分片存储,导致查询数据时需要汇总各个分片的数据
解决方案:
search after,分页时需要排序,每次查询从上一次的排序值开始。但只能向后逐页查询scrool,将排序数据形成快照,保存在内存- 设置上限
高亮显示
在搜索结果中把搜索关键字突出显示
field标签加上pre_tags、post_tags
Java 客户端
JavaRestClient
初始化
|
|
Mapping 映射
结合业务分析所需字段(区分是否需要和是否搜索)
- 搜索字段
- 排序字段
- 展示字段
索引库操作
基于 RestFul格式:
|
|
文档操作
新增文档的 API
|
|
文档批处理
add 多个 index,然后统一请求即可
- 完成批量导入数据
|
|
-
准备文档数据
-
准备请求参数
-
发送请求
RTL 查询
-
SearchRequest对象,发请求 -
解析结果
-
得到 Hits 属性,结果是数组
复合、排序、分页
用指定对象、设置指定参数即可
boolquery、source
|
|
分页:
|
|
高亮:
|
|
数据聚合
对文档数据进行统计、分析
- 桶:对文档做而非女足
- 度量 Metric:计算某些特定值
- 管道 Pipeline:以其他聚合的结果为基础做聚合
DSL
aggs 定义聚合
|
|
RestClient 构造聚合
指定名称、类型、字段
|
|