
绪论
数据结构
-
形式定义:
- 数据结构是一个四元组
Data_Structure=(D,L,S,O)- D是数据元素的有限集
- L是D上客观存在的关系(逻辑结构)
- S是关系L在计算机中的存储表示(存储结构)
- O是D上规定的一组操作。
- 数据结构是一个四元组
-
组成:
-
集合(set)—若干具有共同特征的事物的“聚合”。
-
数据(data) —所有能输入到计算机中的描述客观事物的符号
-
数据元素(data element)—数据的基本单位,也称节点(node)或记录(record)
-
数据项(data item)—有独立含义的数据最小单位,也称域(field)
-
关键码(key)—数据元素中能起标识作用的数据项。
-
关系 —集合中元素之间的某种相关性
-
-
逻辑结构
- 线性结构:一对一,线性表、栈、队列等
- 树形结构
- 图状结构
-
存储结构
- 顺序:借助相对位置表示元素间关系
- 链式:借助指针
- 散列:通过对关键字直接计算
算法
为了解决某类问题而规定的一个有限长的操作序列
-
特性:有穷、确定、可行、功能性
-
目标:正确、可读、健壮、高效率与低存储量需求
-
衡量方法
- 算法的时间特性用执行基本操作次数来度量
- 算法的空间特性用算法运行所需存储量的增长率
线性表、栈与队列
- 线性结构特点:在数据元素的非空有限集中
- 存在唯一一个称作“第一个”的数据元素
- 存在唯一一个称作“最后一个”的数据元素
- 除第一个外,集合中的每个数据元素均只有一个前驱
- 除最后一个外,集合中的每个数据元素均只有一个后继
线性表
- 定义:一个线性表是n个数据元素的有限序列
- 元素个数n = 表长度
- a_1 无直接前驱,a_n 无直接后继
- i 为 a_i 再线性表中的位序
顺序存储
逻辑上相邻 - 物理地址相邻
-
操作
-
插入:复杂度
n/2,算在 i 出的平均移动次数 -
删除:复杂度
(n-1)/2
-
-
优点:
- 逻辑相邻,物理相邻
- 可随机存取任一元素
- 存储空间使用紧凑
-
缺点:
- 插入、删除操作需要移动大量的元素
- 预先分配空间需按最大空间分配,利用不充分
- 表容量难以扩充
链式存储
- 特点:
- 用一组任意的存储单元存储线性表的数据元素,利用指针实现:用不相邻的存储单元存放逻辑上相邻的元素
- 每个数据元素ai,除存储本身信息外,还需存储其直接后继的信息
单链表
结构:
|
|
-
操作
- 查找:
O(n) - 插入、删除:
O(1)
- 查找:
-
特点:
-
动态结构,整个存储空间为多个链表共用
-
不需预先分配空间,指针额外存储空间
-
不能随机读取,查找慢
-
循环链表
表中最后一个结点的指针指向头结点,使链表构成环状
从表中任一结点出发均可找到表中其他结点, 提高查找效率
- 操作与单链表基本一致,循环条件不同:
- 单链表 p 或
p->next=NULL - 循环链表
p->next=h
- 单链表 p 或
双向链表
解决单链表单向性的问题,存储前、后指针
栈
顺序存储
- 定义:
- 限定仅在表尾进行插入或删除操作的线性表,进行操作的一端称栈顶,固定的一端称栈底,不含元素的空表称空栈。
- 先进后出
- 操作:
- 用指针
top始终指向栈顶,初值为 -1 (栈空),终值为 M-1 (栈满)
- 用指针
|
|
链式存储
top 始终指向下一个插入的位置,类似
队列
限定只能在表的一端进行插入,在表的另一端进行删除的线性表,先进先出
链式存储
设队首、队尾指针 front 和rear, front 指向头结点,rear 指向队尾
问题:
- 队列不满时假溢出、队列满时真溢出
解决:
- 队首固定:需要频繁移动 X
- 循环队列:将队列设计成环形,让
让sq[0]接在sq[M-1]之后,若 rear == M,则令 rear = 0- 问题:队空和队满标志一样
- 解决:另设标志位、少用一个元素空间、用一个计数变量
优先队列
不完全遵守先进先出,设有优先级
数组
顺序存储:
-
需要区分列主序、行主序
-
Loc (j1, j2, ... , jn )=Loc (0, 0, ... , 0)+(b2*b3*...*bn*j1 + b3*b4*...*bn*j2+ ...+bn*jn-1+ jn)*l
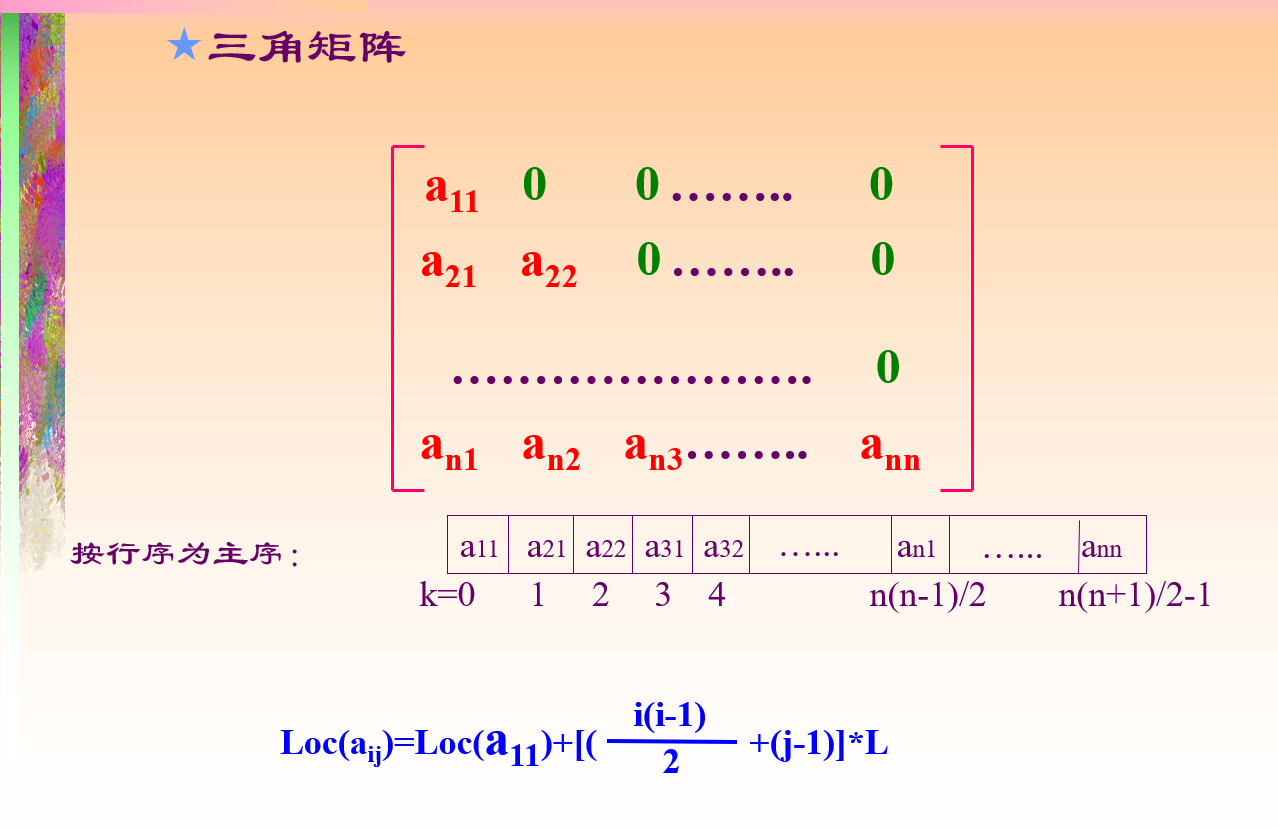
三角矩阵:
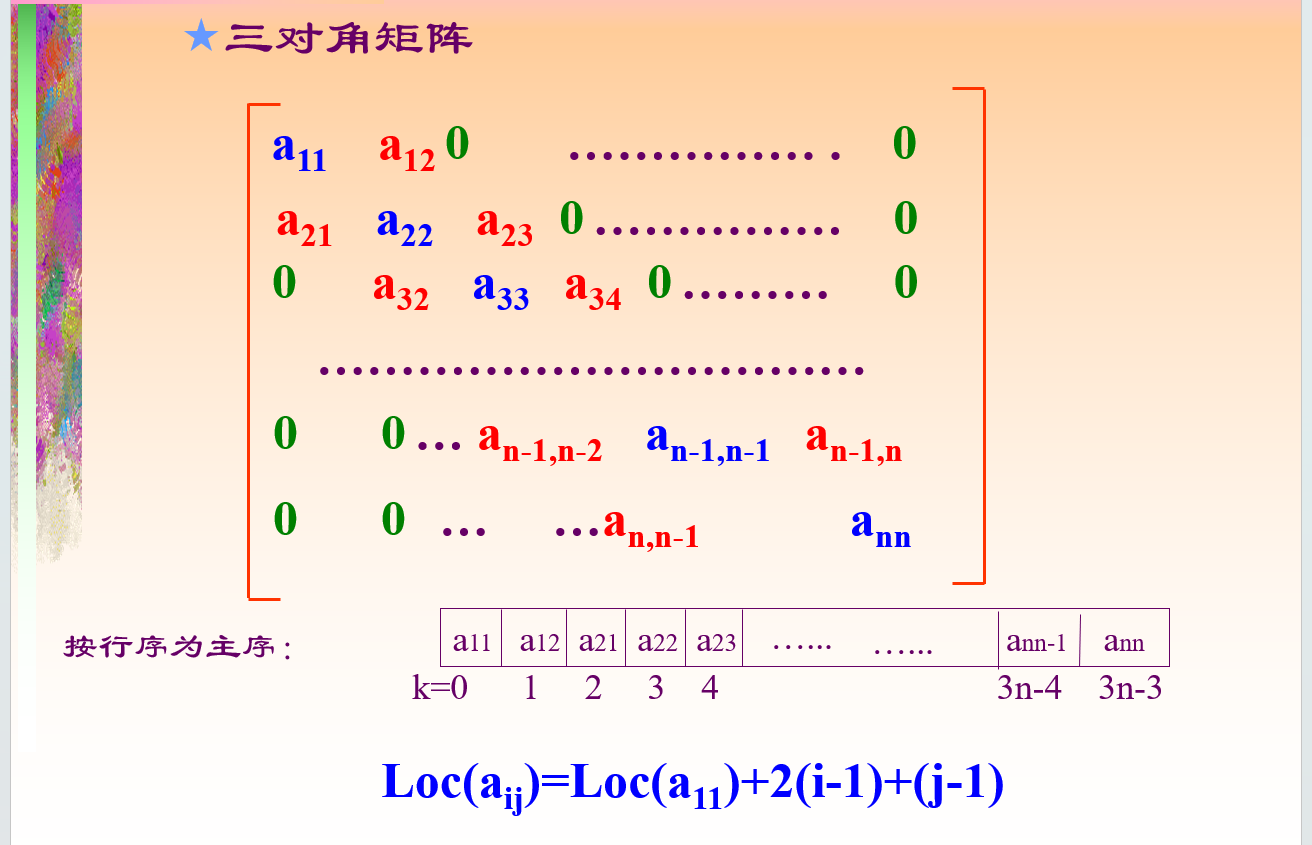
三对角矩阵:
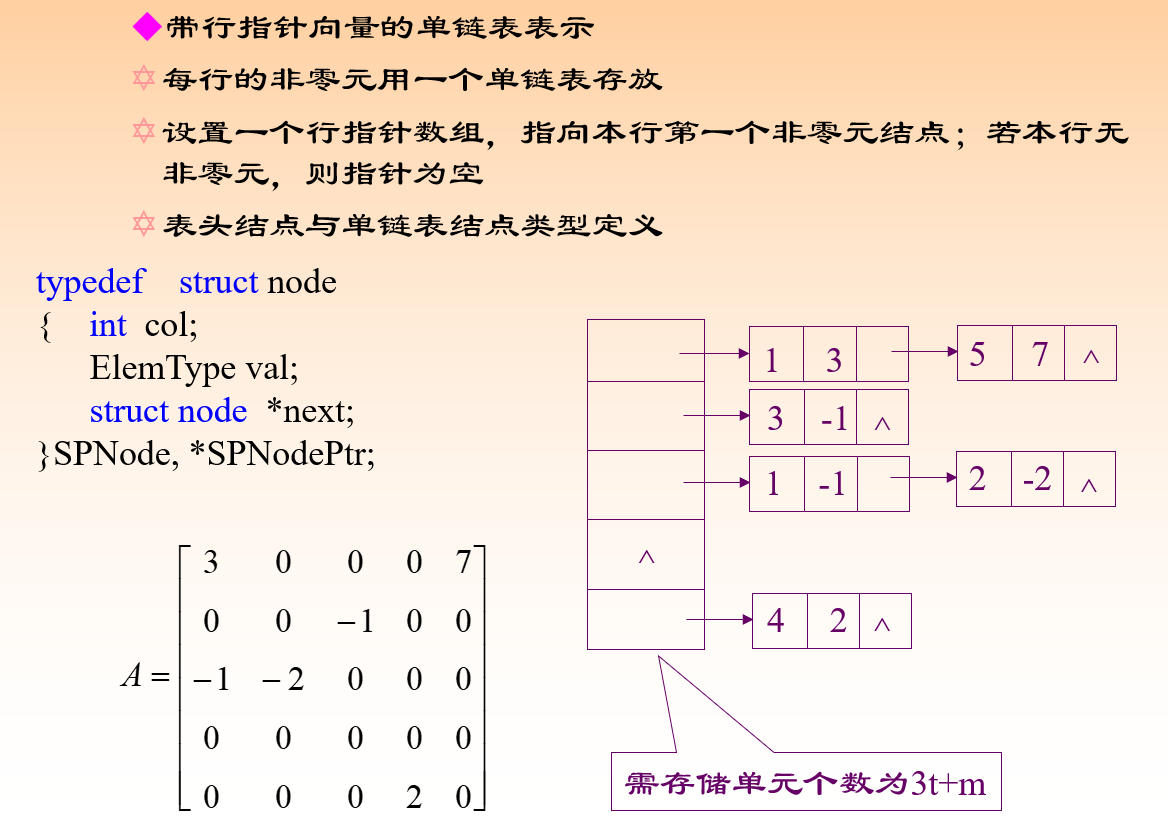
稀疏矩阵:

链式存储
表示矩阵:
数组 + 链表
查找、排序、递归
递归
定义:
- 一个过程或函数出现调用本过程或本函数的成分,称之为递归。
- 若调用自身,称之为直接递归。若过程或函数p调用过程或函数q,而q又调用 p,称之为间接递归。
- 如果一个递归过程或递归函数中递归调用语句是最后一条执行语句,则称这种递归调用为尾递归。
查找
顺序表
- 顺序查找,改变
R[0]以控制结束:
|
|
- 折半查找,对于有序表
|
|
- 索引表查找
- 基本思想:将原表分成若干块,各块内部不一定有序,但表中的块是“分块有序”的,抽取各块中的最大关键字及其起始位置建立索引表。
- 块间顺序:复杂度
1/2 * (n/s + s) + 1(n 长度,分成 n/s 块) - 块间二分:
log_2(n/s + 1) + s/2
|
|
- 哈希表查找
- 以
h(key) 哈希函数作为 key 的记录在表中的位置,常见构造方法有:- 直接哈希:适用于地址集合大小 == 关键字集合大小
- 数字分析:取随机
- 平方取中:取关键字平方后的中间几位
- 折叠:关键字分割后求和
- 除留取余:除某个不大于哈希表长度的数后取余
- 随机数:取随机数
- 冲突处理方法:
- 开放地址:线性探测、平方探测、随机探测 再散列
- 再哈希:将 n 个不同哈希函数排成序列,往下计算
- 链地址:将关键字发生冲突的记录存储在一个线性链表中
- 公共溢出:将发生冲突的放在冲突表中
- ALS 影响因素:
- 选用的哈希函数
- 冲突处理方法
- 哈希表饱和度、装载因子
n/m的大小
- 以
排序
基本概念
-
稳定性:对于任意的数据元素序列,以在排序前后相同关键字数据的相对位置是否改变为依据
-
内外部:
- 无需借助外存,称内部排序
- 数据量巨大,需要借助外村,称外部排序
插入
- 直接插入:
|
|
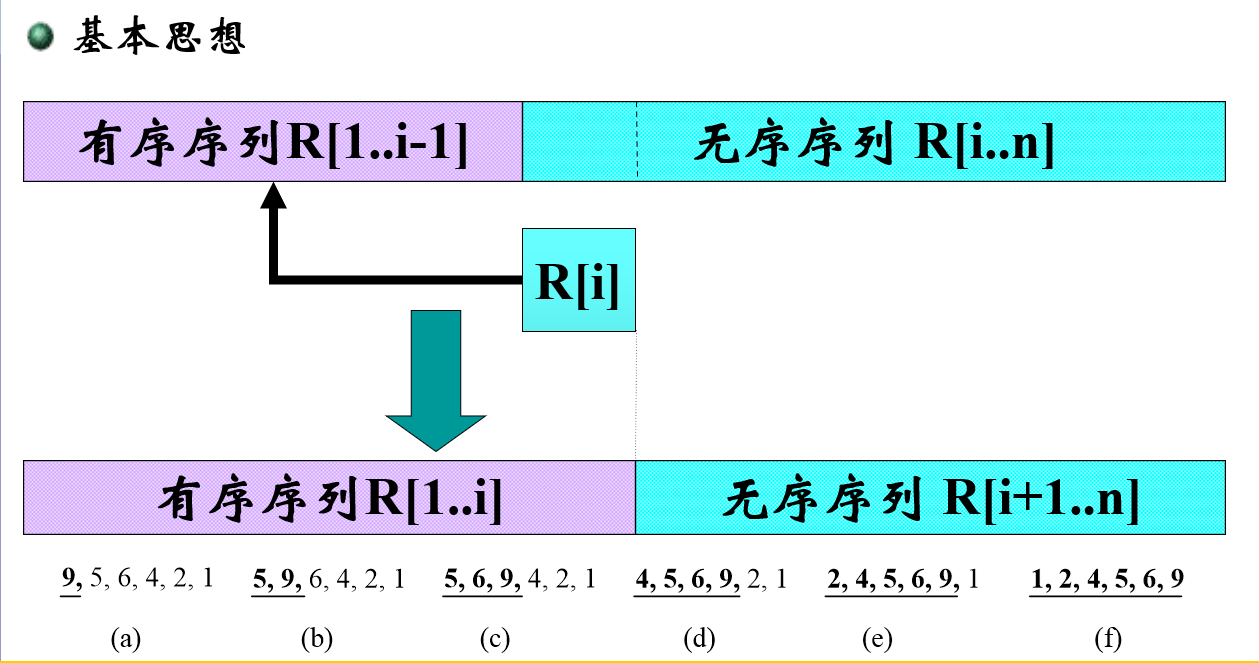
-
折半插入
- 因为
R[1..i-1]是一个按关键字有序的有序序列,则可以利用折半查找实现
- 因为
-
希尔排序
- 对于n较大而且无序时,直接插入排序效率就较低,这时,如果能将序列分成几个较小的序列,对这些较小的序列先排序,然后再对较长的序列进行排序,可一定程度地提高排序效率。
- 步骤:
- 先选取一个小于n的整数di(步长),然后把待排序的序列分成di个组
- 第一趟完成之后,减小步长,再进行分组,再排序,如此知道 d=1
交换
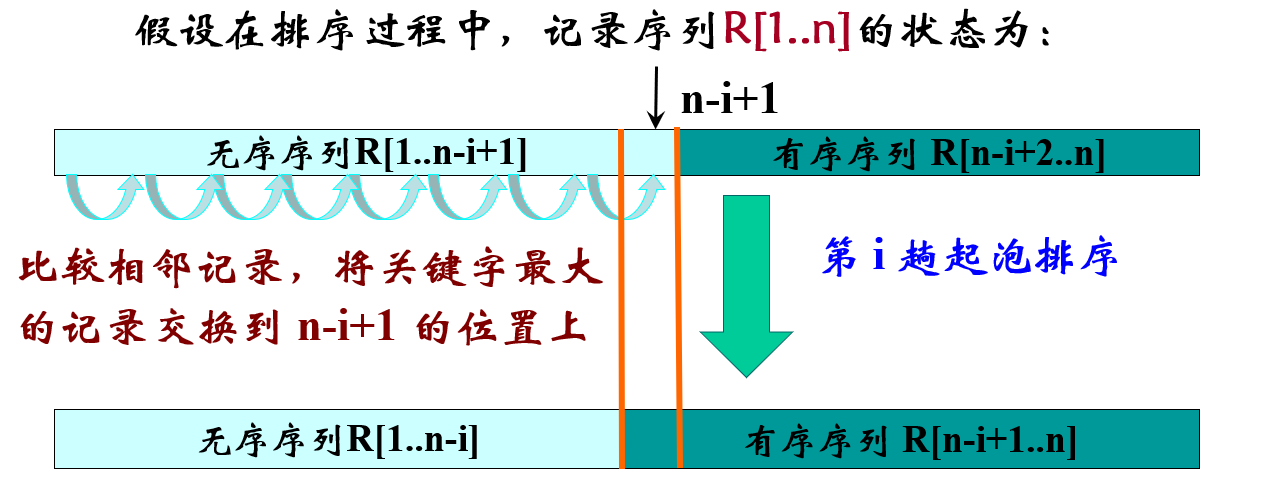
- 冒泡排序
- 基于两两比较及交换,直到某一趟没有发生数据的交换为止。
- 改进:记下上次交换的位置
|
|
图和贪心算法
贪心
顾名思义,贪心算法总是作出在当前看来最好的选择。也就是说贪心算法并不从整体最优考虑,它所作出的选择只是在某种意义上的局部最优选择。当然,希望贪心算法得到的最终结果也是整体最优的。
例:活动安排问题
- 将输入的活动按结束时间的非降序排列,只需 O(n) 即可
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题可用贪心算法求解的关键特征。证明需用归纳证明。
例:0-1 背包问题
贪心不适用,应该比较选择 / 不选择该物品导致的最优方案
例:多机调度问题
图
图G是由两个集合 V(G) 和 E(G) 组成的,记为G=(V,E)其中:V(G)是顶点的非空有限集、E(G)是边的有限集合,边是顶点的无序对或有序对
还有一些基本概念,这里略过,参考离散数学
存储结构
顺序结构
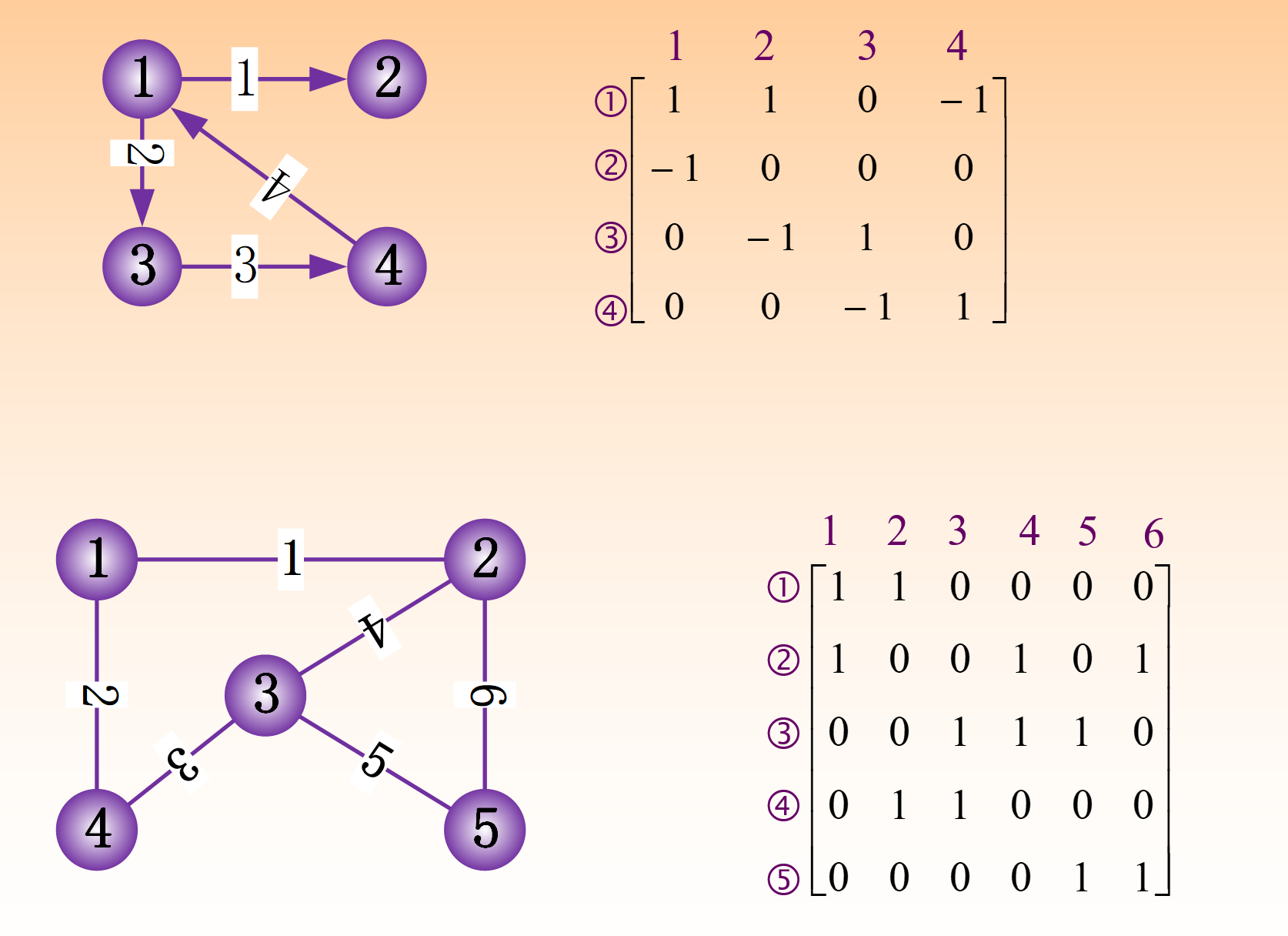
邻接矩阵:表示顶点间关系的矩阵,即点*点的矩阵,若两点间有边相连,则标记为 1(或者有权值)

关联矩阵:表示顶点与边的关联关系,即点*边的矩阵,边的两顶点记为 1 或 -1
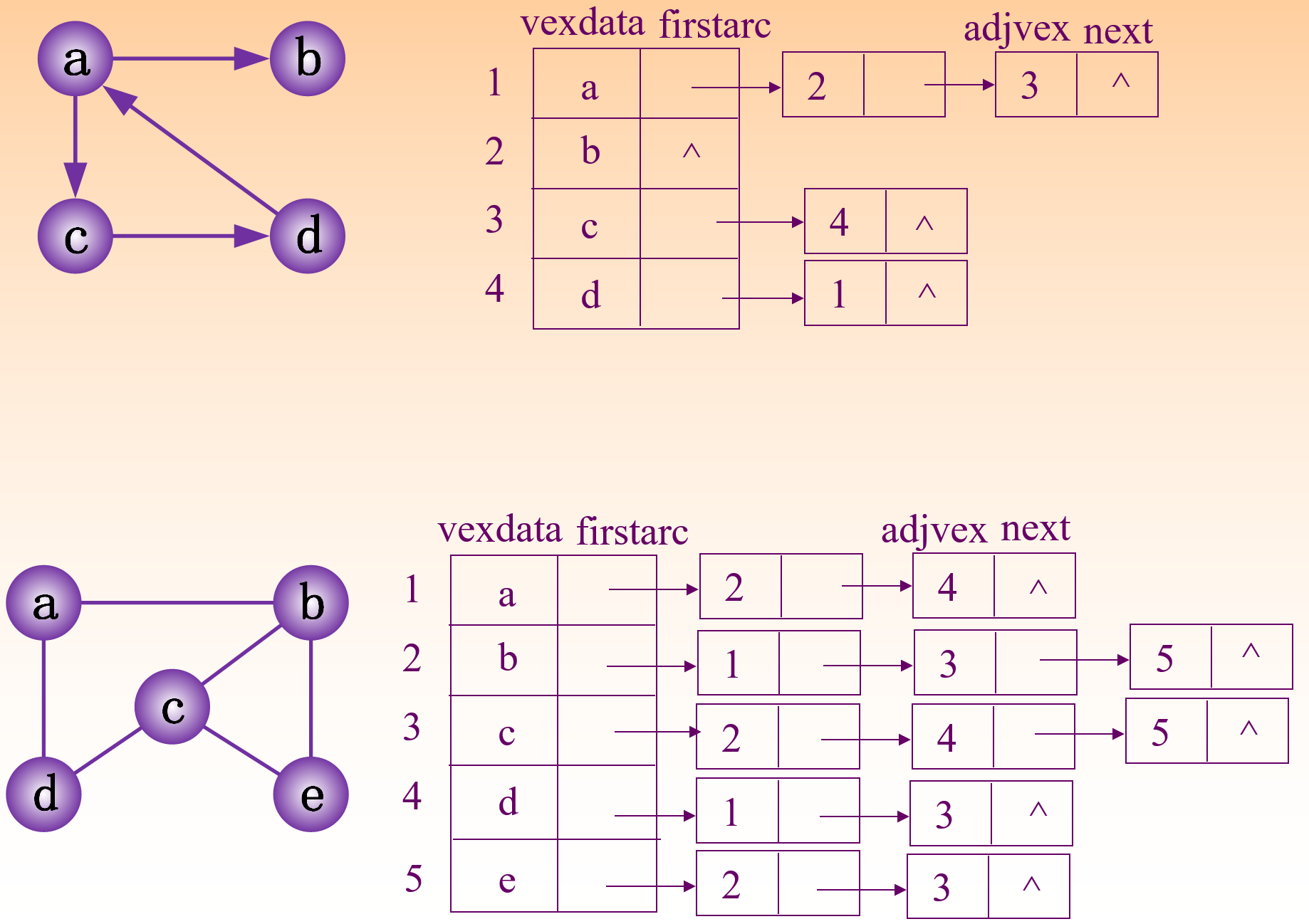
链式存储
邻接表:为图中每个顶点建立一个单链表,第 i 个单链表中的结点表示依附于顶点V的边(有向图中指以V为尾的弧)。即每条边对应一个非头节点,由头指向尾(反过来就是逆邻接表)
十字链表:节点间以弧尾相同连接,包含弧尾、弧头位置以及弧尾弧头相同的下一条弧。
定义:
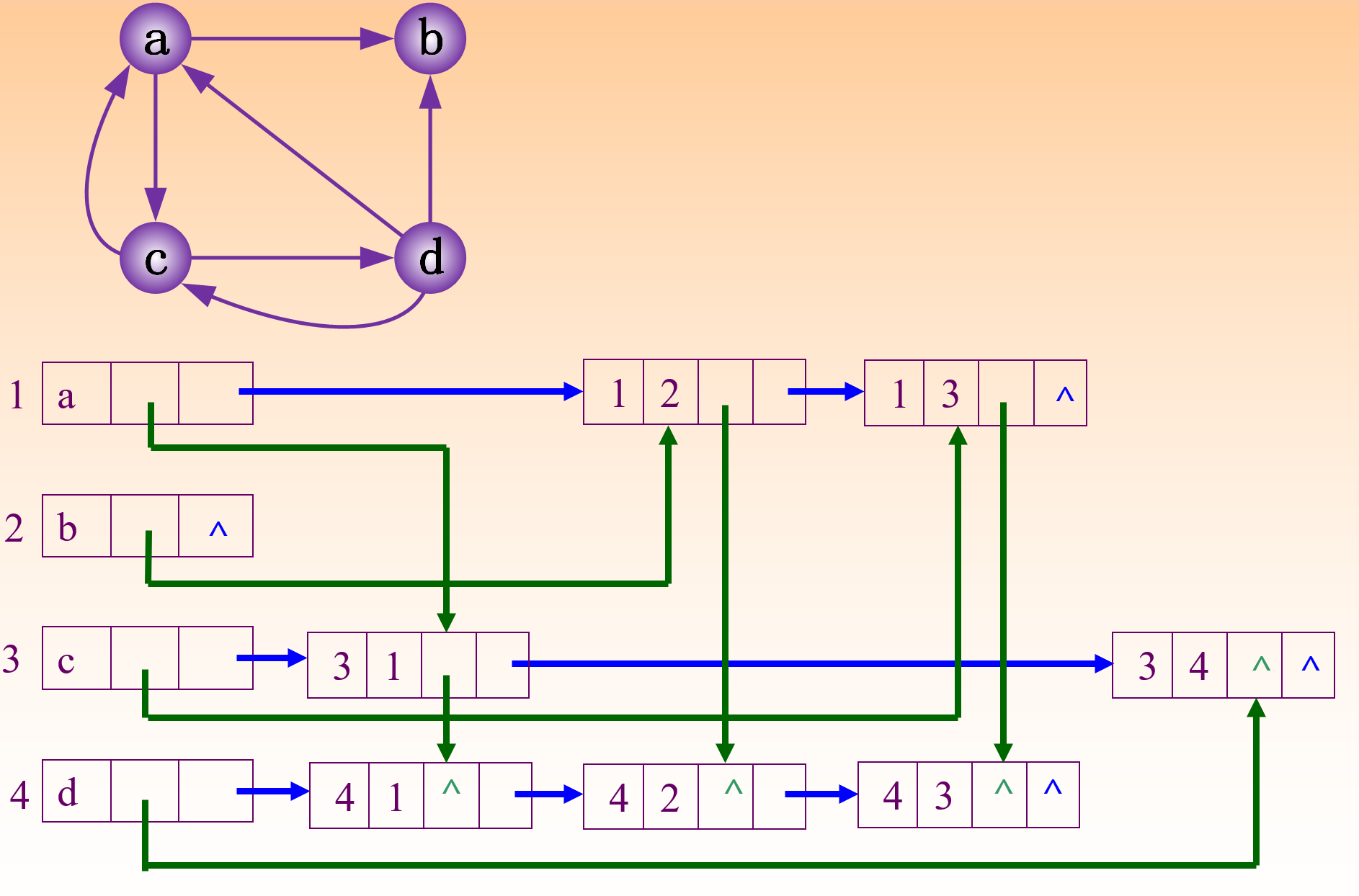
注意一下弧头和弧尾的区分
无向图邻接多重表:节点间以顶点相同互相连接
定义:

图的遍历
深度优先(DFS)
- 方法:从图的某一顶点Vo出发,访问此顶点,然后依次从Vo的未被访问的邻接点出发,深度优先遍历图直至图中有和V0相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未被访问的顶点作起点,重复上述过程,直至图中所有顶点都被访问为止
广度优先(BFS)
- 方法:从图的某一顶点Vo出发,访问此顶点后,依次访问V0的各个未曾访问过的邻接点:然后分别从这些邻接点出发,广度优先遍历图,直至图中所有已被访问的顶点的邻接点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未被访问的顶点作起点,重复上迷过程,直至图中所有顶点都被访问为止